
Anna Krasikov
Künstliche Intelligenz (KI) ist überall: ChatGPT beantwortet Fragen, Sprachassistenten steuern das Smart Home, und Bilderkennungssysteme durchsuchen Millionen Fotos in Sekunden. Doch wie funktioniert KI wirklich? Was steckt hinter Begriffen wie maschinelles Lernen, Deep Learning und Large Language Models?
Dieser Leitfaden erklärt verständlich, wie moderne KI-Systeme arbeiten – von den historischen Anfängen mit ELIZA bis zur Funktionsweise von ChatGPT und Claude. Du erfährst, wie Large Language Models lernen, warum sie trotzdem nicht "denken", und wie du sie verantwortungsvoll nutzt.
Egal, ob du KI beruflich einsetzen oder einfach nur verstehen möchtest – dieser Artikel liefert das nötige Grundwissen für den bewussten Umgang mit künstlicher Intelligenz.
- Was ist Künstliche Intelligenz?
- Anfänge der Künstlichen Intelligenz: Von Denkmaschinen zu Chatbots
- Maschinelles Lernen & Deep Learning – die Grundlage moderner KI
- Was sind Large Language Models (LLMs)?
- „Finde das nächste Wort“ – warum KI nicht „denkt“
- KI richtig nutzen: Praktische Tipps für den Umgang mit ChatGPT & Co.
- Fazit
- FAQ
Was ist Künstliche Intelligenz?
Das Europäische Parlament beschreibt künstliche Intelligenz (KI) als die Fähigkeit einer Maschine, menschliche Fähigkeiten wie logisches Denken, Lernen, Planen und Kreativität zu imitieren (Europäisches Parlament). KI-Systeme nehmen ihre Umwelt über Daten wahr, verarbeiten diese und reagieren zielgerichtet darauf. Diese Fähigkeiten entstehen entweder durch explizite Programmierung oder, zunehmend, durch maschinelles Lernen, d. h. KI Modelle werden mit Daten trainiert (Fraunhofer IKS).
Wichtig dabei:
KI besitzt keine eigene Intelligenz im menschlichen Sinne.
Sie simuliert intelligentes Verhalten, ohne zu verstehen, was sie tut.
Anfänge der Künstlichen Intelligenz: Von Denkmaschinen zu Chatbots
Die Ursprünge der Künstlichen Intelligenz liegen in der Faszination für die menschliche Intelligenz. Schon früh stellten sich Wissenschaftler die Frage, ob sich Denken, Lernen und Problemlösen nicht auch auf Maschinen übertragen lassen. Zu den zentralen Pionieren dieser frühen KI-Forschung zählen Alan Turing, John McCarthy, Marvin Minsky, Allen Newell und Herbert A. Simon. Ihr gemeinsames Ziel war es, zu verstehen, wie menschliche Intelligenz funktioniert und dieses Verständnis auf technische Systeme zu übertragen (Engelke, 2025).
Ein entscheidender Meilenstein war die Dartmouth-Konferenz im Jahr 1956, die heute als Geburtsstunde der KI als eigenständiges Forschungsfeld gilt. Auf dieser Konferenz wurde erstmals der Begriff Artificial Intelligence geprägt und die Vision formuliert, Maschinen zu entwickeln, die Fähigkeiten wie Lernen, Schlussfolgern oder Sprachverarbeitung besitzen (Engelke, 2025).
Der Turing-Test: Wann gilt eine Maschine als intelligent?
Bereits einige Jahre zuvor, im Jahr 1950, hatte Alan Turing eine bis heute einflussreiche Idee vorgestellt: den später sogenannten Turing-Test. Anstatt abstrakt zu definieren, was „Intelligenz“ ist, schlug Turing ein pragmatisches Kriterium vor: Wenn ein Mensch in einem textbasierten Gespräch nicht mehr unterscheiden kann, ob er mit einem anderen Menschen oder mit einer Maschine kommuniziert, dann könne man die Maschine als intelligent bezeichnen (Ertel, 2025).
Wichtig ist dabei: Der Turing-Test misst nicht Verstehen, sondern Verhalten. Es geht ausschließlich darum, ob eine Maschine menschliches Verhalten überzeugend imitieren kann. Zu Beginn war dieser Test eher eine theoretische Idee, denn die technischen Möglichkeiten reichten noch nicht aus, um ihn praktisch umzusetzen.
ELIZA: Der erste Chatbot und die Illusion von Verstehen
Ein erster praktischer Beweis für Turings Überlegungen folgte erst 1966 mit ELIZA, dem weltweit ersten Chatbot. Entwickelt wurde ELIZA von Joseph Weizenbaum am MIT. Das Programm simulierte einen Psychotherapeuten und nutzte dabei einfache sprachliche Techniken wie Spiegelung, Rückfragen und offene Formulierungen, angelehnt an die klientenzentrierte Gesprächsführung nach Carl Rogers (Ertel, 2025).
ELIZA funktionierte ohne echtes Sprachverständnis. Das System arbeitete mit einem Wörterbuch, Schlüsselwörtern und vorgefertigten Antwortmustern. Wurde ein bekanntes Stichwort erkannt, wählte ELIZA eine passende Textschablone aus. Ein klassisches Beispiel:
Benutzer: „Ich habe ein Problem mit meiner Mutter.“
ELIZA: „Erzählen Sie mir mehr über Ihre Familie.“
In diesem Fall erkannte das Programm das Wort „Mutter“ und ordnete es im internen Wörterbuch dem übergeordneten Begriff „Familie“ zu. Anschließend wählte ELIZA eine vorbereitete Antwort aus dem Themenkomplex Familie (Beispiel entnommen aus: ELIZA, der erste Chatbot der Welt). Das Programm reagierte also nicht auf den Inhalt des Problems, sondern lediglich auf ein einzelnes Schlüsselwort und dessen Zuordnung.
Fand das Programm kein verwertbares Stichwort, wich es auf allgemeine Aussagen aus. Trotz dieser einfachen Mechanismen fühlten sich viele Nutzer verstanden – ein Effekt, der selbst Weizenbaum überraschte. ELIZA zeigte eindrucksvoll, wie leicht Menschen einer Maschine Bedeutung, Verständnis und Empathie zuschreiben, obwohl lediglich Muster verarbeitet werden. ELIZA bestand damit keinen formalen Turing-Test, zeigte aber bereits früh, wie überzeugend menschenähnliche Kommunikation auch ohne echtes Verständnis wirken kann.
Bedeutung für die heutige KI
Aus heutiger Sicht war ELIZA technisch stark begrenzt, aber konzeptionell wegweisend. Der Chatbot machte deutlich, dass menschenähnliche Kommunikation nicht zwangsläufig echtes Verstehen voraussetzt. Diese Erkenntnis ist bis heute zentral für die Bewertung moderner KI-Systeme.
Während frühe Systeme wie ELIZA ausschließlich auf festen Regeln und einfachen Mustern beruhten, ermöglichen heutige KI-Modelle durch massive Datenmengen, Rechenleistung und Deep Learning eine völlig neue Skalierung. Dennoch bleibt die grundlegende Idee dieselbe: Maschinen erzeugen intelligente Wirkung, indem sie Muster erkennen und reproduzieren – nicht, indem sie im menschlichen Sinne denken oder verstehen.
Moderne Beispiele hierfür sind ChatGPT, Claude oder Gemini. Sie zeigen eindrucksvoll, wie leistungsfähig diese Technologie geworden ist. Die rasante Entwicklung zeigt sich nicht nur in der Leistungsfähigkeit: Die Fähigkeit der Modelle, komplexe Zusammenhänge zu erkennen, Sprache zu variieren, kreative Ideen zu liefern oder sogar programmatische Aufgaben zu lösen, wächst stetig. Gleichzeitig steigt die Anforderung an die Nutzer, die Grenzen der Systeme zu verstehen und deren Ergebnisse kritisch zu prüfen.
Heute stehen wir an einem Punkt, an dem Large Language Models wie ChatGPT und Claude praktisch jeder Person zugänglich sind und in Bildung, Forschung, Kreativarbeit oder Unternehmensprozesse integriert werden können. Die Geschwindigkeit der Entwicklung verdeutlicht, dass diese Technologien nicht länger Spielereien sind, sondern reale Werkzeuge, deren Einsatz verantwortungsvoll geplant und reflektiert werden muss.
Maschinelles Lernen & Deep Learning – die Grundlage moderner KI
In den letzten Jahren haben KI-Systeme vor allem durch Fortschritte im maschinellen Lernen enorme Entwicklungssprünge gemacht. Der Grund dafür ist banal und mächtig zugleich: riesige Datenmengen und massive Rechenleistung.
Obwohl die Begriffe Künstliche Intelligenz und maschinelles Lernen im Alltag oft synonym verwendet werden, sind sie nicht deckungsgleich. Vereinfacht gesagt gilt: Alles maschinelle Lernen ist KI, aber nicht jede KI basiert auf maschinellem Lernen.
Was ist maschinelles Lernen?
Maschinelles Lernen (Machine Learning) ist ein Teilbereich der KI, der sich mit Algorithmen beschäftigt, die aus Daten lernen, anstatt einem fest programmierten Lösungsweg zu folgen. Ziel ist es, Muster in Trainingsdaten zu erkennen und dieses „Gelernte“ auf neue, unbekannte Daten anzuwenden (Bergmann, IBM).
Beim maschinellen Lernen wird also nicht vorgegeben, wie ein Problem zu lösen ist. Stattdessen verbessert ein Algorithmus seine Ergebnisse durch Wiederholung und Feedback anhand eines definierten Gütekriteriums. Es geht darum, Modelle mit Daten zu trainieren, anstatt manuell Regeln vorzugeben. Ein klassisches Beispiel: Ein Roboter soll ein Objekt von A nach B transportieren. Er kennt das Ziel, aber nicht den optimalen Griff – diesen erlernt er durch Ausprobieren und Rückmeldung aus erfolgreichen Versuchen (Fraunhofer IKS).
Maschinelles Lernen bildet heute das Herzstück vieler KI-Anwendungen, da Modelle eigenständig Entscheidungen oder Vorhersagen treffen können, ohne explizit für jede Situation programmiert zu sein. Maschinelles Lernen lässt sich grob in drei grundlegende Lernarten unterteilen:
- Überwachtes Lernen (Supervised Learning):
Das Modell lernt anhand beschrifteter Daten, z. B. E-Mails mit dem Label „Spam“ oder „Nicht-Spam“. - Unüberwachtes Lernen (Unsupervised Learning):
Das Modell erkennt selbstständig Strukturen in unbeschrifteten Daten, etwa bei der Kundensegmentierung. - Bestärkendes Lernen (Reinforcement Learning):
Das Modell lernt durch Belohnungen und Strafen in einer Umgebung, z. B. in Spielen oder der Robotik.
Typische Aufgabentypen sind dabei:
- Regression (Vorhersage von Zahlenwerten, z. B. Umsatz),
- Klassifikation (Zuordnung zu Klassen, z. B. Kredit genehmigt/abgelehnt),
- Clustering (Gruppierung nach Ähnlichkeiten, z. B. Kundensegmente).
Man kann sich maschinelles Lernen grob wie Lernen beim Menschen vorstellen, nur stark vereinfacht und ohne echtes Verständnis.
Beim überwachten Lernen bekommt die KI sozusagen einen „Spickzettel“ mitgeliefert. Sie sieht viele Beispiele inklusive der richtigen Lösung. Ähnlich wie beim Lernen mit einem Lehrer: „Das ist eine Spam-Mail, das ist keine.“ Nach vielen Beispielen erkennt das Modell typische Muster und kann neue E-Mails selbst einordnen.
Beim unüberwachten Lernen gibt es diesen Spickzettel nicht. Die KI bekommt nur einen großen Datenhaufen und soll selbst herausfinden, was zusammengehört. Das ist vergleichbar mit dem Sortieren von Fotos ohne Beschriftung: Menschen mit ähnlichen Merkmalen landen in einer Gruppe, ohne dass vorher gesagt wurde, wer diese Menschen sind.
Beim bestärkenden Lernen lernt die KI durch Ausprobieren – ähnlich wie beim Training eines Haustiers. Gute Entscheidungen werden belohnt, schlechte „bestraft“. Schritt für Schritt verbessert das System sein Verhalten. Dieses Verfahren wird zum Beispiel bei Spielen, Robotern oder autonomen Systemen eingesetzt.
Die verschiedenen Aufgabentypen beschreiben dabei, was die KI am Ende liefern soll:
- Bei einer Regression geht es um Zahlenwerte, etwa eine Umsatz- oder Preisprognose.
- Bei einer Klassifikation entscheidet die KI zwischen festen Kategorien, zum Beispiel „genehmigt“ oder „abgelehnt“.
- Beim Clustering werden Daten automatisch in Gruppen eingeteilt – etwa Kunden mit ähnlichem Verhalten.
Wichtig ist:
Egal welche Lernart oder Aufgabe – die KI versteht nicht, warum etwas zusammengehört. Sie erkennt nur Muster, die statistisch häufig gemeinsam auftreten.
Was ist Deep Learning?
Ein spezieller und besonders leistungsfähiger Teilbereich des maschinellen Lernens ist das Deep Learning. Es basiert auf künstlichen neuronalen Netzen, die vom menschlichen Gehirn inspiriert sind. In unserem Gehirn gibt es etwa 100 Milliarden Neuronen, die Signale austauschen, verarbeiten und weiterleiten – so wird Denken, Lernen und das Treffen von Entscheidungen ermöglicht. Künstliche neuronale Netze versuchen, diese biologischen Prozesse nachzubilden. Diese sogenannten Deep Neural Networks bestehen aus vielen Schichten und sind in der Lage, extrem komplexe Muster in großen Datenmengen zu erkennen (Fraunhofer IKS).
Beim Deep Learning können KI-Modelle relevante Merkmale selbstständig erkennen und verarbeiten, ohne dass diese vorher manuell festgelegt werden müssen. Genau das macht sie besonders leistungsfähig für hochkomplexe und hochdimensionale Daten wie Bilder, Sprache oder große Textmengen. Anwendungen wie Spracherkennung, Bilderkennung oder generative KI-Systeme basieren heute nahezu ausschließlich auf Deep-Learning-Verfahren.
Man kann sich Deep Learning wie eine mehrstufige Analyse vorstellen:
- Zunächst werden Eingabedaten wie ein Bild, ein Text oder ein Sprachsignal verarbeitet.
- In jeder Schicht des neuronalen Netzes werden andere Aspekte erkannt:
zuerst sehr einfache Merkmale, später immer abstraktere Zusammenhänge (z. B. bei Bildern: Kanten → Formen → Objekte). - Am Ende steht ein Ergebnis, etwa eine Vorhersage, eine Einordnung oder die Generierung neuer Inhalte.
Wichtig dabei:
Das System weiß nicht, was ein Objekt oder ein Wort bedeutet. Es erkennt lediglich Muster, die in den Daten häufig gemeinsam auftreten, aber das in enormer Tiefe und Präzision.
Der entscheidende Unterschied zum klassischen Machine Learning liegt darin, wie viel Vorarbeit der Mensch leisten muss. Während bei herkömmlichen Machine Learning Verfahren relevante Merkmale, z. B. bestimmte Eigenschaften eines Bildes oder Textes, teilweise manuell festgelegt werden, übernimmt Deep Learning diesen Schritt selbstständig. Die Modelle lernen automatisch, welche Merkmale wichtig sind und wie sie miteinander zusammenhängen. Gleichzeitig kann Deep Learning viel größere und komplexere Datenmengen verarbeiten, setzt dafür aber entsprechend hohe Rechenleistung und große Datenbestände voraus.
Deep Learning ist deshalb besonders gut geeignet für Daten mit vielen Ebenen und Wechselwirkungen, etwa Bilder, Videos, Sprache oder große Textsammlungen. Nahezu alle heutigen Formen der KI – von automatischer Übersetzung über autonomes Fahren bis hin zu generativer KI – basieren auf Deep-Learning-Verfahren. Genau dieses Prinzip bildet auch die technische Grundlage sogenannter Large Language Models (LLMs) wie ChatGPT. Dabei handelt es sich um spezialisierte Deep-Learning-Systeme, die Sprache nicht regelbasiert, sondern anhand riesiger Textmengen verarbeiten und Muster in sprachlichen Zusammenhängen lernen.
Was sind Large Language Models (LLMs)?
Large Language Models (LLMs) sind eine spezielle Kategorie von Deep-Learning-Modellen, die auf riesigen Mengen an Textdaten trainiert wurden. Sie sind in der Lage, menschliche Sprache zu verstehen, zu verarbeiten und neue Inhalte zu generieren, ohne dabei wirklich „zu verstehen“, was sie sagen – sie erkennen und reproduzieren Muster in Texten.
Diese Sprachmodelle wie ChatGPT oder Claude basieren auf neuronalen Netzwerken und nutzen spezielle Verfahren, die besonders gut für Sprache geeignet sind. Eine zentrale Rolle spielt dabei die sogenannte Transformer-Architektur. Sie sorgt dafür, dass das Modell nicht nur Wort für Wort liest, sondern Zusammenhänge über ganze Sätze und längere Texte hinweg berücksichtigen kann – ähnlich wie Menschen beim Lesen den Kontext im Blick behalten.
GPT-3 wurde beispielsweise mit rund einer Billion Wörtern trainiert und verfügt über 175 Milliarden sogenannte Parameter. Diese kann man sich vereinfacht als innere Regler vorstellen, mit denen das Modell lernt, welche Wörter, Satzteile und Bedeutungen häufig zusammen auftreten und wie stark sie sich gegenseitig beeinflussen (Ertel, 2025).
Die Funktionsweise lässt sich vereinfacht so erklären:
- Training auf Texten: Das Modell liest große Mengen an Text und lernt Sprachmuster, Logik und Fakten.
- Token-Vorhersage: Es berechnet, welches Wort (oder Token) mit hoher Wahrscheinlichkeit als Nächstes folgt, basierend auf dem bisherigen Kontext.
- Generierung neuer Inhalte: Aus den gelernten Wahrscheinlichkeiten kann das Modell Texte erstellen, Fragen beantworten, Zusammenfassungen liefern oder Inhalte übersetzen.
Typische Anwendungsbereiche von LLMs sind:
- Textgenerierung (Artikel, E-Mails, Code)
- Zusammenfassungen und Recherchen
- Chatbots und Wissensmanagement
- Übersetzungen
Übrigens: Mit gutmütigen Gesprächspartnern können LLMs heute den Turing-Test bestehen, also menschenähnliche Gespräche führen, ohne tatsächlich zu verstehen, was sie sagen.
LLMs sind damit die logische Weiterentwicklung von Deep Learning: Sie zeigen, wie die Prinzipien tiefer neuronaler Netze auf Sprache angewendet werden, um riesige Textmengen zu verarbeiten und kontextbezogen nutzbare Ergebnisse zu liefern. In der Praxis erzeugen sie auf Basis erlernter Muster Texte, beantworten Fragen oder übersetzen Inhalte – ohne wirklich zu „verstehen“, was sie sagen. Im nächsten Schritt schauen wir uns genauer an, wie LLMs dabei Wort für Wort neue Inhalte generieren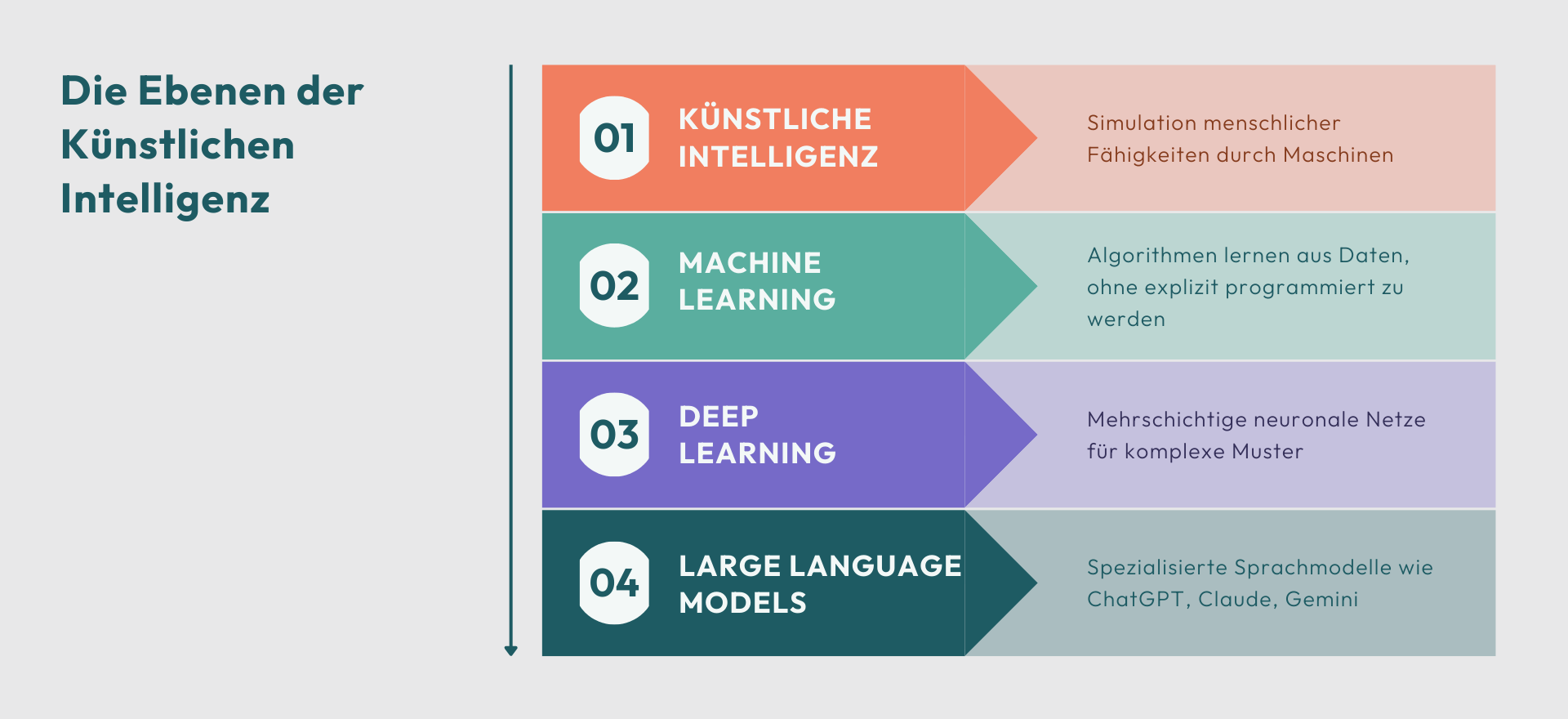
„Finde das nächste Wort“ – warum KI nicht „denkt“
So beeindruckend moderne KI-Systeme wirken: Sie denken nicht. Large Language Models (LLMs) wie ChatGPT basieren auf einem einfachen statistischen Prinzip: „Finde das nächste Wort“ (Engelke, 2025).
Beim Training lernt das Modell anhand riesiger Textmengen, welches Wort in einem gegebenen Kontext mit welcher Wahrscheinlichkeit als Nächstes kommt. Dieses Prinzip wird millionen- bis milliardenschwer trainiert – mit unmittelbarem Feedback im Trainingsprozess. Das Ergebnis sind Texte, die kohärent, verständlich und menschlich wirken. Nicht, weil das Modell versteht, was es sagt, sondern weil es Wahrscheinlichkeiten auswertet.
Ein LLM weiß also nicht, was ein Wort oder ein Satz bedeutet. Es weiß nur, was in diesem Kontext wahrscheinlich gut passt. Es ahmt menschliche Sprache nach, es denkt nicht.
Doch um Sprache auch über längere Textpassagen hinweg sinnvoll zu verarbeiten, braucht das Modell einen Mechanismus, der den Kontext berücksichtigt – hier kommen Transformer ins Spiel.
Transformer – der Kontext-Motor
Das „T“ in GPT steht für Transformer, eine spezielle Architektur, die 2017 von Google vorgestellt wurde (Attention Is All You Need, 2017). Sie ermöglicht es dem Modell, den Kontext über lange Textabschnitte hinweg zu berücksichtigen. Anders als frühere Methoden wie Markov-Ketten, die nur einfache Wortfolgen analysierten, erkennt der Transformer, welche Wörter im Satz besonders wichtig für den Zusammenhang sind. So kann das Modell relevante Wörter für die Vorhersage des nächsten Tokens auswählen und irrelevante Wörter ignorieren. Transformer sind also der Mechanismus, der LLMs erlaubt, Sprache „im Kontext“ zu verarbeiten.
Trotz dieser Fähigkeit, kohärente Texte zu erzeugen, speichern LLMs kein echtes Wissen.
Sprachmodelle sind keine Wissensmodelle
LLMs speichern keine Fakten wie in einer Datenbank. Sie merken sich nicht, dass „Albert Einstein Physiker war“. Sie speichern lediglich Wahrscheinlichkeiten von Wortfolgen, basierend auf den Trainingsdaten. Transformer helfen dabei, nur die Wörter zu berücksichtigen, die für die Vorhersage relevant sind.
Das bedeutet: LLMs können korrekte Aussagen generieren, wissen aber nicht, ob sie stimmen. Sie sind Werkzeuge zur Textgenerierung, nicht zur Wissensspeicherung. Deshalb sollten ihre Ergebnisse immer geprüft werden.
Kurz gesagt: Die Magie hinter KI ist Statistik. Das Modell prognostiziert das nächste Wort, ähnlich wie andere Modelle versuchen, das Wetter von morgen aus historischen Daten vorherzusagen.
Auch wenn moderne LLMs mittlerweile auf Echtzeit-Websuche zugreifen können, ändert das nichts an diesem Grundprinzip – sie bleiben Sprachmodelle, keine Wissensdatenbanken.
Halluzinationen – wenn KI „erfindet“
Aus diesem Grund kann das Modell gelegentlich Informationen erfinden, die plausibel klingen, aber falsch oder nicht belegt sind. Fachleute sprechen dabei von sogenannten Halluzinationen.
Beispiel: Auf die Frage „Wer war der erste Mensch auf dem Mond?“ könnte ein schlecht trainiertes Modell eine falsche Jahreszahl oder sogar einen erfundenen Namen nennen, wenn es die Wahrscheinlichkeit der Wortfolgen falsch einschätzt.
Halluzinationen zeigen, dass Sprachmodelle zwar überzeugend schreiben können, aber nicht prüfen, ob etwas stimmt. Deshalb ist es immer wichtig, generierte Inhalte kritisch zu hinterfragen und zu verifizieren. Um dieses Problem zu adressieren, haben viele Anbieter ihre LLMs um Websuche-Funktionen erweitert. Das macht LLMs jedoch nicht zu Suchmaschinen und verändert auch nicht ihr grundlegendes Funktionsprinzip.
LLMs sind keine Suchmaschinen
Klassische LLMs wie ChatGPT oder Claude sind in ihrer Grundform keine Wissensmodelle und können die von ihnen erzeugten Informationen nicht auf Richtigkeit prüfen. Sie arbeiten ausschließlich mit den Mustern, die sie während ihres Trainings gelernt haben – ohne Zugriff auf aktuelle Informationen oder das Internet.
Mittlerweile bieten jedoch viele LLM-Anbieter Erweiterungen an, die eine Echtzeitsuche ermöglichen:
- ChatGPT verfügt über eine integrierte Internetsuche, die bei Bedarf aktiviert werden kann und aktuelle Informationen aus dem Web abruft.
- Claude kann ebenfalls auf Websuche zugreifen und Inhalte in Echtzeit recherchieren.
- Perplexity AI: Hier sucht zuerst ein Suchmaschinen-Index nach relevanten Webseiten und Snippets, danach analysiert ein LLM die gefundenen Inhalte und erstellt daraus eine zusammenhängende Antwort inklusive Quellenangabe.
Wichtig zu wissen: In kostenlosen Versionen ist die Echtzeitsuche oft limitiert oder mit Einschränkungen versehen. Zudem verbraucht jede Anfrage an ein LLM – auch bei kleinen Recherchen – deutlich mehr Energie und Rechenressourcen als eine klassische Websuche.
Auch Websuche-Integrationen eliminieren Halluzinationen nicht vollständig: LLMs interpretieren gefundene Informationen weiterhin statistisch und können Quellen falsch kombinieren oder Details missverstehen.
Deshalb gilt: Für schnelle, einfache Recherchen oder die Suche nach spezifischen Informationen sind klassische Suchdienste wie Google oder Bing oft effizienter und ressourcenschonender. LLMs mit Suchfunktion eignen sich besonders dann, wenn Informationen nicht nur gefunden, sondern auch analysiert, zusammengefasst oder in einen größeren Kontext eingeordnet werden sollen. Die Ergebnisse sollten jedoch immer kritisch geprüft werden.
KI richtig nutzen: Praktische Tipps für den Umgang mit ChatGPT & Co.
Gute Prompts schreiben: Die wichtigsten Prinzipien
Die Qualität der KI-Antwort hängt stark vom Prompt ab. Formulierung, Kontext und Zielbeschreibung beeinflussen das Ergebnis massiv. Schlechte Ergebnisse sind daher häufig kein KI-Problem, sondern ein Kommunikationsproblem.
Hier sind die wichtigsten Prinzipien für gutes Prompting:
1. Aufgabe klar definieren
Was du erreichen willst: Beschreibe präzise und in einfacher Sprache, welches Ergebnis du erwartest – Information, Analyse, Text-Entwurf, Ideensammlung oder Entscheidungshilfe.
Beispiel:
"Erstelle eine 200-Wörter-Zusammenfassung, die erklärt, wie ChatGPT funktioniert – verständlich für Nicht-Techniker."
2. Kontext liefern
Hintergrund ist entscheidend: Erkläre, wer du bist, für wen der Text ist, welches Vorwissen vorhanden ist und in welchem Zusammenhang die Antwort genutzt wird.
Beispiel:
"Ich bin Projektmanagerin ohne Tech-Hintergrund und muss meinem Team erklären, was Deep Learning ist. Wir evaluieren gerade KI-Tools für unser Unternehmen."
3. Beispiele oder Referenzen geben
Zeige, was du meinst: Konkrete Beispiele, gewünschte Tonalität oder Referenztexte helfen dem Modell, deine Erwartung zu verstehen.
Beispiel:
"Erkläre es so, dass es jemand ohne Fachkenntnisse versteht – nicht wie ein Wikipedia-Artikel, sondern wie ein guter Erklärbär-Thread auf Twitter. Kurz, konkret, mit Alltagsbeispielen."
4. Bewertungskriterien nennen
Was macht eine gute Antwort aus? Definiere, woran du erkennst, ob die Antwort passt – Länge, Tonalität, Struktur, Fakten-Dichte oder spezifische Anforderungen.
Beispiel:
"Die Antwort sollte:
- Maximal 150 Wörter lang sein
- Keine Fachbegriffe ohne Erklärung enthalten
- Mindestens ein konkretes Beispiel enthalten"
5. Format und Struktur festlegen
Wie soll das Ergebnis aussehen? Bestimme das Ausgabeformat: Stichpunkte, Fließtext, Tabelle, FAQ, E-Mail-Entwurf oder Präsentationsfolie.
Beispiel:
"Erstelle eine Tabelle mit 3 Spalten: KI-Tool | Stärken | Schwächen"
6. Iterativ nachschärfen (Iterate)
Perfektion entsteht im Dialog: Ein Chat ist kein Einmalprompt. Ergänzungen, Korrekturen und Nachfragen sind ausdrücklich Teil des Prozesses. Verfeinere schrittweise.
Beispiel:
Erster Prompt → Ergebnis prüfen → "Mach es kürzer und ergänze ein Beispiel aus der Praxis" → Ergebnis prüfen → etc.
Beispiel:
"Ich möchte eine praxisorientierte Analyse erstellen, wie ein mittelständisches Produktionsunternehmen KI in der Auftragsplanung nutzen könnte. Hintergrund: 150 Mitarbeiter, Excel-basiert, kein tiefes Tech-Wissen im Team. Liste drei konkrete Anwendungsfelder auf, die sofort umsetzbar sind. Orientiere dich am Stil eines Beratungs-Memos – klar strukturiert, ohne Fachjargon. Die Antwort sollte: Maximal 300 Wörter lang sein, keine ungeklärten Fachbegriffe enthalten, sofort umsetzbare Lösungen zeigen Erstelle eine Tabelle mit: 'Anwendungsfeld', 'Datenbasis', 'Nutzen' Fasse am Ende in einem Satz zusammen, welches Vorgehen priorisiert werden sollte."
Mehr über Prompt Engineering lernen
Die hier vorgestellten Prinzipien sind ein guter Einstieg. Wer tiefer einsteigen möchte, findet bei den folgenden Quellen umfassende Guides und weiterführende Techniken:
- Best practices for generating AI prompts - Work Life by Atlassian
- Strategien für Prompt-Design - Gemini API - Google AI for Developers
- Prompt engineering overview - Claude API Docs
Fehlersuche: Warum macht die KI nicht, was ich will?
KI-Outputs enttäuschen selten wegen der Technologie – häufiger wegen des Prompts. Typische Ursachen sind:
- unklare oder widersprüchliche Anweisungen
- fehlender Kontext
- zu hohe Erwartungen (z. B. exakte Zahlen ohne Datenbasis)
- Vermischung mehrerer Ziele in einem Prompt
Oft hilft es, die Anfrage neu zu formulieren – so, als würde man einer fachfremden Person erklären, was genau zu tun ist.
Wie man Halluzinationen reduziert – praktische Tipps
Halluzinationen lassen sich nicht vollständig vermeiden, aber ihr Risiko lässt sich deutlich senken. Entscheidend ist dabei weniger die KI selbst als die Art der Interaktion.
1. Keine suggestiven Fragen stellenFragen wie
„Warum ist Methode X die beste Lösung?“
setzen eine Annahme voraus. Das Modell wird diese bestätigen – selbst dann, wenn sie nicht stimmt.
Besser ist:
„Welche Vor- und Nachteile hat Methode X?“
oder
„In welchen Fällen ist Methode X sinnvoll – und in welchen nicht?“
Fordere das Modell aktiv auf, Grenzen zu benennen:
„Wenn es keine verlässlichen Informationen gibt, weise bitte darauf hin.“
„Nenne Annahmen und Unsicherheiten explizit.“
Auch wenn Quellen nicht immer perfekt sind, hilft die Aufforderung:
„Begründe jede Aussage kurz.“
„Kennzeichne Vermutungen.“
Bitte um eine klare Struktur, z. B.:
- Gesicherte Informationen
- Annahmen
- Einschätzungen
Das zwingt das Modell zu mehr Zurückhaltung.
5. Bei kritischen Themen: hybride Ansätze nutzenFür Recherche, aktuelle Informationen oder belastbare Fakten sollten LLMs mit Suchsystemen kombiniert werden, z. B. über Suchmaschinen oder hybride Tools. LLMs eignen sich dann besonders für Zusammenfassung, Strukturierung und Einordnung, nicht für die Primärrecherche.
Stärken und Schwächen von KI: Was LLMs können (und was nicht)
Um KI sinnvoll einzusetzen, ist es entscheidend zu verstehen, wo ihre Stärken liegen und wo ihre Grenzen sind. Large Language Models sind Werkzeuge für Sprache und Strukturierung, keine Entscheider oder Wahrheitsinstanzen. Die folgende Übersicht zeigt, wofür LLMs gut geeignet sind und wo sie an ihre Grenzen stoßen:
|
Sprachmodelle sind stark bei: |
Sie sind schwach bei: |
|---|---|
|
|
|
|
|
|
|
|
Wichtig: Die Verantwortung für Interpretation, Bedeutung und Entscheidung bleibt beim Menschen.
Datenbasis, Bias und blinde Flecken
LLMs reflektieren ihre eigenen Grenzen nicht. Sie sagen selten: „Das weiß ich nicht.“
Ihre Trainingsdaten sind historisch gewachsen und enthalten Verzerrungen, kulturelle Prägungen und systematische Voreingenommenheiten wider – im Fachjargon als Bias bezeichnet.
Diese werden nicht bewusst reproduziert, wirken aber dennoch – oft subtil.
Deshalb ist kritische Reflexion unverzichtbar, insbesondere bei sensiblen Themen wie Personal, Bewertung, Recht oder Ethik.
Gute Ergebnisse entstehen im Zusammenspiel
KI ist kein Autor und kein Entscheider, sondern ein Co-Pilot.
Die besten Resultate entstehen, wenn Menschen Ziel, Kontext, Bewertung und Verantwortung übernehmen und die KI als Werkzeug nutzen.
Datenschutz und Verantwortung
Prompts sind Daten. Wer interne, personenbezogene oder vertrauliche Informationen eingibt, muss wissen, wo diese verarbeitet werden und ob das zulässig ist. Datenschutz und rechtliche Rahmenbedingungen sind kein Randthema, sondern Voraussetzung für den professionellen Einsatz.
Bei sensiblen Daten sollte zudem geprüft werden, ob und wie Eingaben zur Weiterentwicklung der Modelle genutzt werden und ggf. diese Einstellungen deaktiviert werden. Viele Anbieter bieten mittlerweile Optionen, das Training mit eigenen Daten auszuschließen – diese sollten bei beruflicher oder vertraulicher Nutzung aktiv geprüft und eingestellt werden.
Nachhaltigkeit
Das Training und der Betrieb großer KI-Modelle verbrauchen erhebliche Mengen an Energie und Rechenressourcen. Das Training von GPT-3 verursachte beispielsweise einen CO₂-Ausstoß, der dem von mehreren Transatlantikflügen entspricht. Auch jede einzelne Anfrage an ein LLM benötigt deutlich mehr Energie als eine klassische Websuche.
Dieser ökologische Fußabdruck wird in der öffentlichen Diskussion zunehmend thematisiert. Für einen verantwortungsvollen Umgang mit KI bedeutet das: Setze KI gezielt dort ein, wo sie echten Mehrwert bietet – nicht reflexartig für jede Kleinigkeit. Die Frage „Brauche ich dafür wirklich KI?" ist nicht nur ökonomisch, sondern auch ökologisch relevant.
KI ersetzt kein Denken – sie beschleunigt es
LLMs sparen Zeit, senken Einstiegshürden und helfen beim Strukturieren komplexer Themen.
Sie ersetzen jedoch weder Fachwissen noch Verantwortung.
Der Mehrwert entsteht dort, wo menschliche Urteilskraft und künstliche Sprachfähigkeit bewusst zusammenwirken.
Fazit
Künstliche Intelligenz ist kein menschliches Denken, sondern die Simulation intelligenten Verhaltens durch Maschinen. Sie kann lernen, planen, Muster erkennen und Sprache erzeugen, ohne wirklich zu verstehen, was sie tut. Historische Systeme wie ELIZA haben bereits gezeigt, dass menschenähnliche Interaktion möglich ist, auch wenn kein echtes Verständnis vorhanden ist.
Moderne KI, etwa Large Language Models wie ChatGPT (GPT-5) oder Claude, beruht auf maschinellem Lernen und Deep Learning. Sie verarbeiten riesige Datenmengen, erkennen Muster und erzeugen darauf basierende Antworten – beeindruckend menschenähnlich, aber statistisch und nicht bewusst. Transformer-Architekturen ermöglichen es, Kontext über längere Textpassagen zu berücksichtigen, doch das Wissen ist nicht gespeichert, sondern entsteht aus Wahrscheinlichkeiten und Mustern.
KI ist stark bei Sprache, Strukturierung, Ideen und Zusammenfassungen, jedoch schwach bei Bewertung, ethischen Entscheidungen und der Beurteilung von Fakten. Halluzinationen und Bias zeigen die Grenzen der Systeme deutlich. Deshalb gilt: Die Verantwortung liegt beim Menschen. KI ist ein Werkzeug, ein „Co-Pilot“, der menschliche Fähigkeiten beschleunigt und ergänzt, nicht ersetzt.
Verantwortungsvoller Einsatz umfasst dabei:
- Kritische Reflexion und Überprüfung der Ergebnisse
- Bewusste Nutzung sensibler Daten unter Datenschutzgesichtspunkten
- Abwägung von ökologischem und ökonomischem Aufwand
- Kombination von menschlichem Urteil und maschineller Unterstützung
Kurz: Künstliche Intelligenz beschleunigt Denken, ersetzt es aber nicht. Wer ihre Stärken und Grenzen kennt, kann sie gezielt einsetzen, um komplexe Aufgaben effizienter zu lösen, ohne die Verantwortung aus der Hand zu geben.
Du möchtest tiefer einsteigen?
Dieser Leitfaden vermittelt die Grundlagen – für die konkrete Umsetzung in eurem Unternehmen braucht es mehr: eine strategische Einschätzung, wann KI sinnvoll ist, welche Risiken bestehen und wie Entscheidungen fundiert getroffen werden.
Wir unterstützen Unternehmen dabei, Technologie-Entscheidungen strategisch zu treffen – jenseits von Hypes und Schnellschüssen.
Jetzt Kontakt aufnehmen oder einen unverbindlichen Discovery Call buchen!
Quellen: